关于项目
项目背景: 设计并实现了一个基于 Linux 平台的轻量级 HTTP 服务器,采用多 Reactor 多线程高并发模型,通过 epoll 提供高效的 I/O 复用。结合自动增长缓冲区、定时器和异步日志等技术,实现了高性能和稳定运行的目标。
主要工作
内存优化:设计了内存池和 LFU 缓存,减少内存碎片,提升内存使用效率。
高效事件处理:利用 epoll 多路复用机制,高效监听和处理客户端连接及数据传输事件。
高并发模型:基于 Reactor 模型,实现 One Loop per Thread,支持多客户端并发连接。
动态缓冲区:实现自动增长缓冲区,动态调整大小以适配不同请求,优化内存分配。
连接管理:使用小根堆实现高效定时器,管理连接超时时间,防止长期空闲连接浪费资源。
异步日志:设计异步日志模块,基于单例模式和阻塞队列,实现高效日志写入,避免同步写入的性能开销。
关于项目
介绍一下
本项目是一个高性能的WEB服务器,使用C++实现,项目底层采用了多线程多Reactor的网络模型,并且在这基础上增加了内存池,高效的双缓冲异步日志系统,以及LFU的缓存。
服务器的网络模型是主从reactor加线程池的模式,IO处理使用了非阻塞IO和IO多路复用技术,具备处理多个客户端的http请求和ftp请求,以及对外提供轻量级储存的能力。
项目中的工作可以分为两部分,
一部分是服务器网络框架、日志系统、存储引擎等一些基本系统的搭建,
另一部分 是为了提高服务器性能所做的一些优化,比如缓存机制、内存池等一些额外系统的搭建。
最后还对系统中的部分功能进行了功能和压力测试。对于存储引擎的压力测试,
在本地测试下,存储引擎读操作的QPS可以达到36万,写操作的QPS可以达到30万。对于网络框架的测试,使用webbench创建1000个进程对服务器进行60s并发请求,测试结果表明,对于短连接的QPS为1.8万,对于长连接的QPS为5.2万。
项目难点
根据工作分为两部分
一部分是服务器网络框架,日志系统,存储引擎等一些基本系统的搭建,这部分的难点主要就是技术理解和选型,以及将一些开源的框架调整后应用到我的项目中去。
另一部分就是性能优化方面,比如缓存机制,内存池等一些额外系统的搭建。这部分的难点在于找出服务器的性能瓶颈所在,然后结合自己的想法突破瓶颈,提高服务器性能。
遇到的困难,怎么解决
一方面是对技术理解不够深刻,难以选出合适的技术框架,这部分主要是阅读作者的技术文档,找相关的解析文章看
另一部分是编程遇到的困难,由于工程能力不足出现bug,这部分主要是通过日志定位bug,推断bug出现的原因并尝试修复,如果以自己能力无法修复,先问问ai能提供什么思路,或者搜索相关的博客。
内存优化
设计了内存池和 LFU 缓存
缓存机制
为什么选择LFU
因为最近加入的数据因为起始的频率很低,容易被淘汰,而早期的热点数据会一直占据缓存。
高效事件处理:
epoll 多路复用机制
采用非阻塞I/O模型,执行系统调用就立即返回,不检查事件是否发生,没有立即发生返回-1,errno设置为在处理中。所以要采用I/O通知机制(I/O复用和SIGIO信号)来得知就绪事件。
1 | I/O多路复用技术 |
IO多路复用
LT与ET
LT:水平触发模式,只要内核缓冲区有数据就一直通知,只要socket处于可读状态就一直返回sockfd;是默认的工作模式,支持阻塞IO和非阻塞IO
ET:边沿触发模式,只有状态发生变化才通知并且这个状态只会通知一次,只有当socket由不可写到可写或由不可读到可读,才会返回sockfd:只支持非阻塞IO
为什么用epoll,其他多路复用方式以及区别
高并发模型
基于 Reactor 模型,实现 One Loop per Thread
Reactor模式通常用同步I/O模型实现
Proactor模式通常用异步I/O模型实现
- 主线程往epoll内核事件表注册socket读就绪事件
- 主线程调用epoll_wait等待socket上有数据可读
- 当socket上有数据可读时,epoll_wait通知主线程,主线程将socket可读事件放入请求队列
- 工作线程被唤醒,读数据处理请求,然后往epoll内核事件表注测socket写就绪事件
- 主线程调用epoll_wait等待socket可写
- 当socket可写,epoll_wait通知主线程,主线程将socket可写事件放入请求队列
- 睡眠在请求队列的工作线程被唤醒,往socket上写入服务器处理客户请求的结果
动态缓冲区
实现自动增长缓冲区
1. 核心数据结构
1 | class Buffer { |
采用vector作为底层容器,自动处理内存分配/释放
读写指针分离设计,支持零拷贝操作
零拷贝是指计算机执行IO操作时,CPU不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及CPU的拷贝时间。它是一种I/O操作优化技术。
2. 自动增长机制
(1) 扩容触发条件
当writableBytes() < 待写入数据量时自动扩容
通过vector的resize实现:
1 | void append(const char* data, size_t len) { |
(2) 智能扩容策略
1 | void makeSpace(size_t len) { |
3. 高性能IO优化
(1) 双缓冲区读操作
1 | ssize_t readFd(int fd, int* saveErrno) { |
使用readv系统调用实现分散读
优先使用主缓冲区空间,不足时使用栈缓冲区过渡
避免频繁扩容带来的性能损耗
(2) 写操作优化
1 | ssize_t writeFd(int fd, int* saveErrno) { |
直接使用write系统调用
peek()返回有效数据起始指针,避免内存拷贝
4. 关键特性总结
智能扩容:按需自动增长,兼顾内存使用效率
零拷贝设计:读写指针分离,减少内存拷贝
双缓冲策略:栈空间+主缓冲区组合优化IO性能
线程安全:单次IO操作原子性保证
内存高效:自动回收已读区域空间
典型工作流程:
读取数据时优先使用主缓冲区空间
空间不足时暂存到栈缓冲区
触发自动扩容后合并数据
写入数据时直接操作有效数据区域
连接管理
使用小根堆实现高效定时器,管理连接超时时间
1 | using Entry = std::pair<Timestamp, Timer*>; // 以时间戳作为键值获取定时器 |
1 | // 定时器管理红黑树插入此新定时器 |
异步日志
设计异步日志模块,基于单例模式和阻塞队列
日志系统是多生产者,单消费者的任务场景
多生产者负责把日志写入缓冲区,单消费者负责把缓冲区数据写入文件
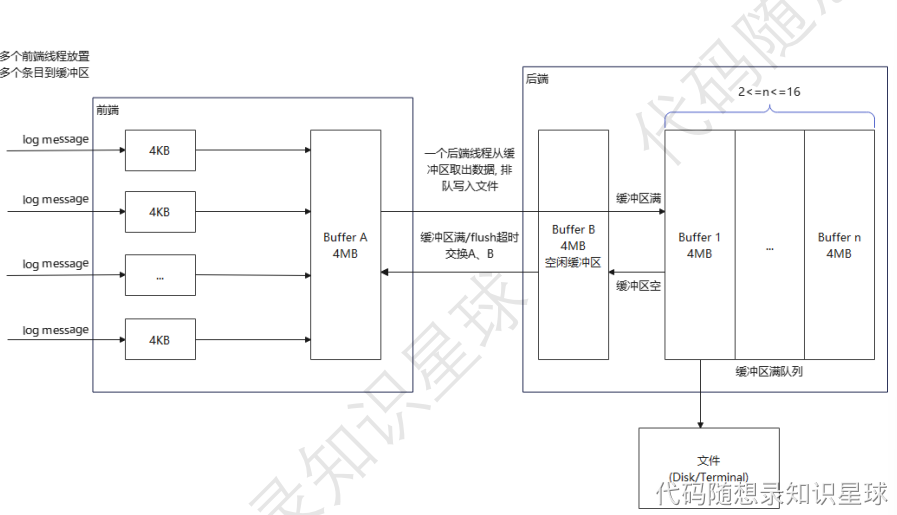
前端往后端写,后端往硬盘写
双缓冲技术 ,写满就交换,相当于将多条日志拼接成一个大buffer传送到后端然后写入文件,减少了线程开销