该例子是一个生产者一个消费者,缓冲区是1,如果缓冲区很大这个问题就会被忽视了,如果生产者和消费者数量增加,那么死锁概率也会增加
1 | //错误的 |
问题是,为什么前一个线程执行完的broadcast后,consumer(12896)为什么没被唤醒,而后面的producer(12897)被唤醒了,而且例子中只有一个生产者和一个消费者,缓冲区大小为1
1 | ------Consumer: begin, execution count: 12896------ |
该例子是一个生产者一个消费者,缓冲区是1,如果缓冲区很大这个问题就会被忽视了,如果生产者和消费者数量增加,那么死锁概率也会增加
1 | //错误的 |
问题是,为什么前一个线程执行完的broadcast后,consumer(12896)为什么没被唤醒,而后面的producer(12897)被唤醒了,而且例子中只有一个生产者和一个消费者,缓冲区大小为1
1 | ------Consumer: begin, execution count: 12896------ |
模板函数和模板类有的时候可能需要对传入的不同类型进行不同的处理,比如说有的模板传入int或double类型都可以处理,但是传入char型则会出错,这时就需要模板特化的方式。
全特化即将模板类型里的所有类型参数全部具体指明之后处理,如下
1 | template<typename T,typename C> |
template<>中为空,代表所有类型都在下面特殊化处理,上面相当于对int,int进行了分别的处理,其他类型依然是泛化版本。
还是以上面给的例子为基础,特化func()成员函数,当A的模板参数为<int,double>时,调用特化版的func()。
1 | template<> |
类模板偏特化(局部特化):顾名思义,只特殊化几个参数或者一定的参数范围
1 | template<typename T,typename C,typename D> |
template<>括号中存留的参数是依然可以任意填的参数。
STL中的一个个数偏特化例子:
1 | //泛化 |
1 | //特化 |
记住这种情况的template<>中还是要填上原有的大类型,且const T*属于T*不属于const T。
注意范围二字,比如const int属于int的一个小范围,int *和const int*属于int的一个小范围,int&属于int的一个小范围,int&&属于int的一个小范围
1 | template<typename T> |
STL中的一个范围偏特化例子: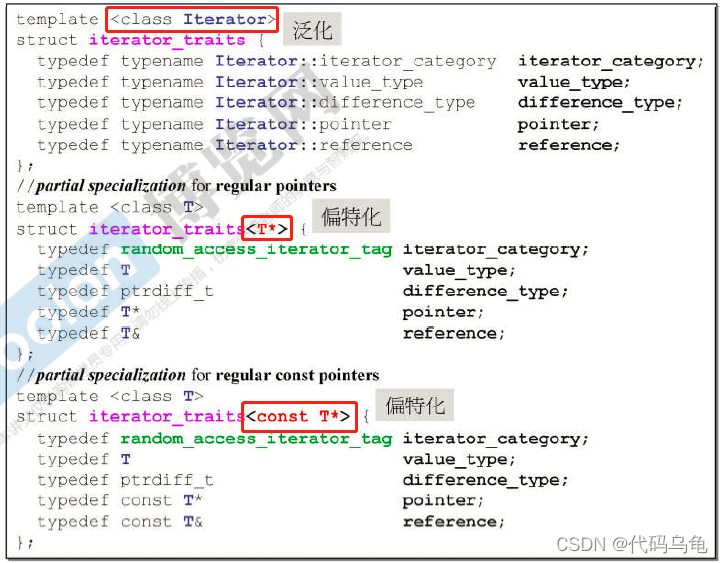
标准C++类std::string的内存共享和Copy-On-Write技术_std::string重新分配内存拷贝字符串-CSDN博客
string的懒拷贝
当函数返回一个静态字符串时,这个字符串存储在函数的静态存储区域中。这个静态存储区域在程序的整个生命周期内都存在,并且在程序加载时分配,在程序退出时释放。
在你描述的情况中,函数GetIPAddress返回一个静态字符串,它在动态链接库的地址空间中分配。当动态链接库被释放时,这个地址空间也被释放,导致返回的静态字符串指向的内存变得无效。但是,由于字符串对象的值是存储在这个无效内存中的,所以在后续程序中使用这个字符串时就会出现未定义行为,因为访问了无效的内存地址。
这种情况下,即使程序在后续没有使用到这个字符串,当程序退出时,会调用字符串对象的析构函数,尝试释放这个无效内存,进而导致内存访问异常,导致程序崩溃。
ssh:使用 -v 选项检查日志gcc:使用 -v 选项打印各种过程make:使用 -nB 选项查看完整命令历史perf - “采样” 状态机strace - 追踪系统调用将日志文件重定向到vim进行各种操作
1 | strace -f g++ a.cc |& vim - |
执行 grep 命令进行过滤,可以通过 :! 来运行外部命令并将结果显示在 vim 中。
步骤如下:
在 vim 中输入:
1 | :!grep "关键词" 文件名 |
或者,你可以直接对 vim 缓冲区的内容使用管道进行过滤:
1 | :%!grep "关键词" |
:!grep "关键词":会在当前终端执行 grep,但不影响你在 vim 中的内容。:%!grep "关键词":会将当前文件内容通过管道传递给 grep,然后将过滤结果替换当前文件的内容。例如:
1 | :%!grep "error" |
这会将所有包含 error 的行保留,并替换掉当前缓冲区的内容。
如果包含.h这种,使用转义字符
1 | :%!grep "\.h" |
gdb调试
目的:复现jyy的调试过程
直接执行make debug会报错,显示no file问题就是boot里的文件是bootblock.o而不是boot.o,所以在其Makefile里添加
1 | cp bootblock.o boot.o |
复制一份,如何就再次执行make debug 就会出现新的bug
1 | gdb.error: "/home/cgz/work/os-workbench/abstract-machine/am/src/x86/qemu/boot/boot.o": not in executable format: file format not recognized |
显示格式不能识别,问gpt回答为该种格式不能直接调试,需要启动qemu,连接调试,事实也是这样,
问题不是这个。所以就是Makefile里缺少-ggdb
需要-ggdb提供调试信息,gdb才能调试可执行文件
在
1 | abstract-machine/am/src/x86/qemu/boot/Makefile |
添加-ggdb可以同时解决打印不出来的问题,不实现stdio里的printf函数也能打印
设置$AM_HOME为pa的框架,改写Makefile不起作用
但是改写为直接clone的
1 | /home/cgz/work/os-workbench/abstract-machine/am/src/x86/qemu/boot/Makefile |
就能正常使用printf,但是用make debug还是没有标记
1 | gdb.error: "/home/cgz/work/os-workbench/abstract-machine/am/src/x86/qemu/boot/boot.o": not in executable format: file format not recognized |
造成这个的原因是在文件上没有gdb可以识别的标记
解决方法应该是加上-ggdb应该就可以
但是还是报错没有标记,把bulid生成的.o文件全部删除,再执行也一样。
尝试把py程序代码手动输入,看看能否解决
1 | debug: |
1 | # Register the quit hook |
提取出命令
1 | qemu-system-i386 -s -S -machine accel=tcg -smp "1,sockets=1" -drive format=raw,file=build/hello-x86-qemu & |
同样的报错
已解决
把Makefile的两行交换位置即可
1 | SRCS := start.S main.c |
递归算法的时间复杂度
彻底搞懂递归的时间复杂度_递归排序的时间复杂度-CSDN博客
二分查找(Binary search):一般发生在一个数列本身有序的时候,要在有序的数列中找到目标数,所以它每次都一分为二,只查一边,这样的话,最后它的时间复杂度是O(logn)
二叉树遍历(Binary tree traversal):如果是二叉树遍历的话,它的时间复杂度为O(n)。因为通过主定理可以知道,它每次要一分为二,但是每次一分为二之后,每一边它是相同的时间复杂度。最后它的递推公式就变成了图中T(n)=2T(n/2)+O(1)这样。最后根据这个主定理就可以推出它的运行时间为O(n)。当然这里也有一个简化的思考方式,就是二叉树的遍历的话,会每一个节点都访问一次,且仅访问一次,所以它的时间复杂度就是O(n)
二维矩阵(Optimal sorted matrix search):在一个排好序的二维矩阵中进行二分查找,这个时候也是通过主定理可以得出时间复杂度是O(n),记住就可以了
归并排序(merge sort):所有排序最优的办法就是nlogn,归并排序的时间复杂度就是O(nlogn)
错误递归
1 | Polynomial& Polynomial::operator=(const Polynomial& p) { |
1 | Polynomial& Polynomial::operator=(const Polynomial& p) { |
封装,继承和多态
重写与重载的本质区别是,加入了override的修饰符的方法,此方法始终只有⼀个被你使用的方法
| 场景 | 返回类型 | 原因 |
|---|---|---|
| 操作当前对象并希望支持链式调用 | 返回引用(Type&) |
提高性能,支持链式操作。 |
| 提供对内部成员的直接访问 | 返回引用(Type&) |
允许外界修改内部数据,避免拷贝开销。 |
| 计算新结果并返回 | 返回值(Type) |
返回一个新对象,不修改原始对象,符合语义要求。 |
后置 ++ 或 -- |
返回值(Type) |
符合“返回操作前的状态”的语义要求,需返回旧值副本。 |
| 局部变量或临时对象 | 返回值(Type) |
局部对象的生命周期短,不能返回局部对象的引用,否则将导致未定义行为(悬空引用) |